The Kruskal-Wallis test, derived from first principles
statistics
hypothesis testing
Deriving the Kruskal-Wallis test from scratch, using a pain management trial to show where ANOVA falls short.
Author
Andreas Bogossian
Published
April 26, 2026
Let’s say that we want to test the effects of pain management protocols. We have 45 post-surgical patients randomized to three groups: opioid-only, NSAID + nerve block and multimodal. 48 hours after their operations, each patient marks their pain on a 0–10 visual analog scale (VAS). The question that the clinic is interested in is whether the three different protocols produce different pain levels or not.
ANOVA [1] is a popular test for testing whether group means are equal. The problem with ANOVA in the pain scale example is that the pain scores are typically right-skewed (clustering around 2-4) and with small sample sizes, the within-group variance can be inflated by some observations being at the right tail (8-10). ANOVA computes an F-statistic as a ratio of between-group variance to within-group variance. If the within group variance is inflated, ANOVA needs a larger between-group variance to detect a difference.
The Kruskal-Wallis test solves this problem. The KW test replaces raw scores with their ranks in the pooled dataset (see Figure 2) and tests whether the ranks cluster by treatment. Under the null hypothesis, the ranks should equally be distributed to the groups.
NoteNotation used in this post
Symbol
Meaning
K
Number of groups
j
Group index, j \in \{1, \ldots, K\}
n_j
Number of observations in group j
N
Total sample size N = \sum_j n_j
x_{ij}
The i-th observation in group j
R_{ij}
Rank of x_{ij} among all N pooled observations
R_j
Rank sum of group j: R_j = \sum_i R_{ij}
\bar{R}_j
Mean rank of group j: \bar{R}_j = R_j / n_j
\bar{R}
Grand mean rank: \bar{R} = (N+1)/2
H
Kruskal-Wallis test statistic
F
ANOVA F-statistic
\chi^2(K-1)
Chi-square distribution with K-1 degrees of freedom
The pain trial
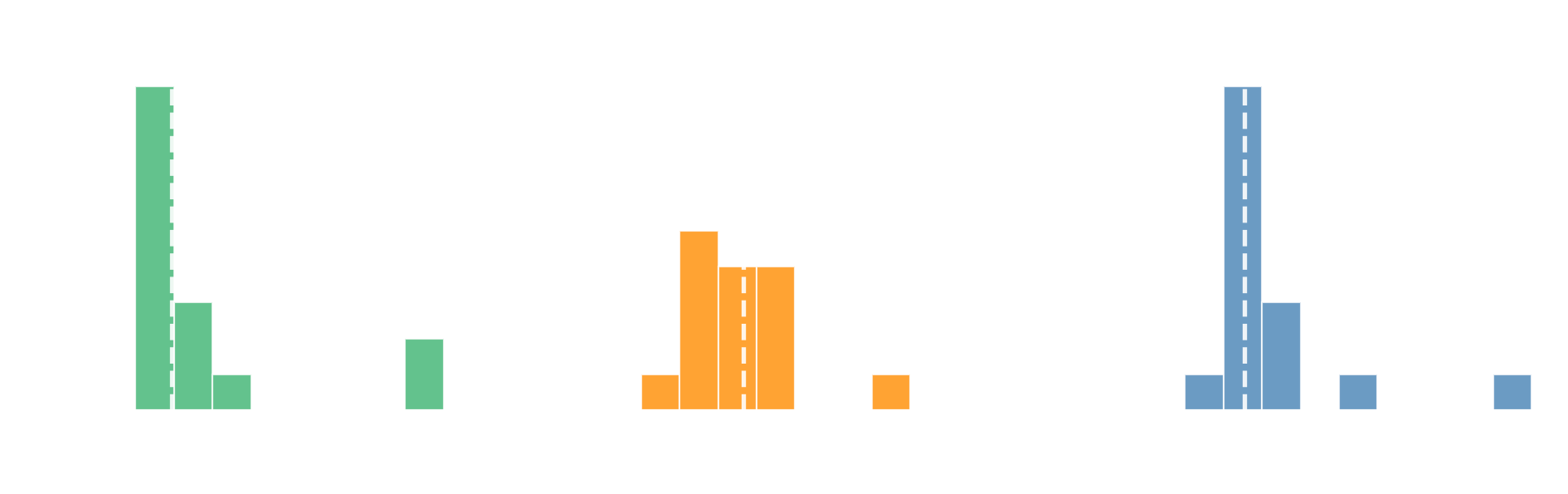
This post will use a made up example: the data will have three groups of 15 patients with NRS scores at 48 hours post surgery. The Figure 1 shows both the theoretical (Gamma) distributions where the samples are drawn from and the actual samples. Then Table 1 summarizes the data.
Figure 1: VAS pain scores at 48 h post-surgery for three protocols. Dashed line shows the group median.
Table 1: Summary statistics for the three pain management protocols.
Protocol
n
Mean
Median
SD
Multimodal
15
2.57
1.8
2.21
NSAID + nerve block
15
3.21
3.3
1.37
Opioid-only
15
3.93
3.2
1.92
The key insight: order is enough
For deducing whether one protocol produces less pain than another, we don’t need to know how much less. We only need to know who ranks lower. Thus we use a ranking transformation. The animation in Figure 2 shows how the data points are transformed into ranks.
Figure 2: Each dot is one of the 45 patients, coloured by protocol. Drag to 1: each pain score is replaced by its rank in the pooled dataset, spreading the dots uniformly. The pooled row fades in to show all 45 ranks in sequence.
Deriving the H statistic
Setting up the problem
Abstracting from the medical example, let’s say that we have K groups with the number of observations in each group being n_1, ..., n_K. Then the total number of observations is N = \sum_j n_j. After combining the observations into one pool and ranking them (as shown in Figure 2), let R_{ij} be the rank of the i-th observation in group j.
The goal is to test whether the groups share the same distribution with each other. Transforming this into a null hypothesis becomes
H_0: \text{the ranks } 1, 2, \ldots, N \text{ are randomly distributed across groups}
So the next question to answer is: what does a large deviation from the random distribution look like and how can we measure the deviation?
Expected rank mean under H_0
Under H_0, every rank is equally likely to fall into any group. Then the expected value of a single rank R drawn from the uniform set \{1, \ldots, N\} is
\mathbb{E}[R] = \frac{1}{N} \sum_{r=1}^{N} r = \frac{1}{N}\frac{N(N+1)}{2} = \frac{N+1}{2} \tag{1}
The expected mean rank in all groups is \bar{R} = \frac{N+1}{2}, regardless of the individual group sizes. The only thing that matters is the total sample size. If H_0 is true, all groups’ mean ranks should hover around \bar{R}.
Building the test statistic
A natural way to measure deviation from the null is the squared distance of each group’s mean rank \bar{R}_j from the expected grand mean:
T = \sum_{j=1}^{K} n_j \left(\bar{R}_j - \frac{N+1}{2}\right)^2 \tag{2}
Here n_j is the size of group j to weight the penalty of bigger groups more because we have more information of them. This structure is extremely similar to ANOVA that is defined as the between group sum of squared deviations from each group mean from the global mean:
To turn T from Equation 2 into a statistic with a known null distribution, we need to normalize it by the variance of the ranks. With Equation 1, the variance for a discrete uniform distribution on \{1, \dots, N\} is:
By analogy with the ANOVA F-statistic, we normalise T by SS_{\text{total}}/(N-1), where the total rank sum-of-squares for the complete set of ranks \{1,\dots,N\} is SS_{\text{total}} = N\sigma^2_R = \frac{N(N^2-1)}{12}:
H = (N-1)\cdot\frac{T}{SS_{\text{total}}} = \frac{12}{N(N+1)} \sum_{j=1}^{K} n_j \left(\bar{R}_j - \frac{N+1}{2}\right)^2
The factor 12/[N(N+1)] scales H so that its expected value under H_0 equals K-1, which is exactly the degrees-of-freedom parameter of a chi-square distribution. For large N, H \xrightarrow{d} \chi^2(K-1) under H_0.
Back to the pain trial
Now that we’ve shown the mathematical difference between ANOVA and the Kruskal-Wallis test, we can compute the p-values using both of the tests and compare them.
import numpy as npfrom scipy import statsN =sum(len(g) for g in groups)K =len(groups)all_scores = np.concatenate(groups)ranks = stats.rankdata(all_scores)idx =0rank_groups = []for g in groups: rank_groups.append(ranks[idx : idx +len(g)]) idx +=len(g)grand_mean_rank = (N +1) /2H, p_kw = stats.kruskal(*groups)F, p_anova = stats.f_oneway(*groups)
Grand mean rank (null expectation): 23.0
Protocol
Rank sum
Mean rank
Deviation
Multimodal
212
14.17
-8.83
NSAID + nerve block
378
25.20
+2.20
Opioid-only
444
29.63
+6.63
Test
Statistic
df
p-value
Kruskal-Wallis
H = 11.034
2
0.0040
ANOVA
F = 1.976
2
0.1513
The multimodal group’s mean rank is well below 23.0 (the grand mean rank), the opioid-only group’s mean rank is well above it. The NSAID + nerve block is quite close to the mean rank. The H-statistic is able to quantify the spread. The chi-square p-value tells us whether a deviation this large would occur by chance under the null. With p < 0.05, we reject. The KW-test rejects the null, ANOVA doesn’t. This shows that the KW-test is able to quantify the differences between distributions when they are heavily skewed better than ANOVA.
NoteWhat KW doesn’t tell
A statistically significant KW result only says that something differs, not which pairs differ. To investigate which pairs differ, the Dunn test [2] fits this problem well.